Upload File to Ec2 Instance Boto Python

![]()
Ambar
Posted on • Updated on
Upload file to S3 -> Launch EC2 instance
Problem Argument
Scenario
A user wants to run a data-processing (e.1000. ML) workload on an EC2 case. The data to be processed in this workload is a CSV file stored in an S3 bucket.
Currently the user has to manually spin up an EC2 case (with a user-information script that installs the tools and starts the data processing), later uploading the information (a CSV file) to their S3 bucket.
Wouldn't information technology be great if this could be automated? And then that creation of a file in the S3 bucket (from any source) would automatically spin up an appropriate EC2 example to procedure the file? And creation of an output file in the same bucket would likewise automatically terminate all relevant (east.m. tagged) EC2 instances?
Requirements
Use Instance 1
When a CSV is uploaded to the inputs "directory" in a given S3 bucket, an EC2 "data-processing" instance (i.due east. tagged with {"Purpose": "data-processing"}) should be launched, merely only if a "data-processing" tagged instance isn't already running. I instance at a time is sufficient for processing workloads.
Employ Case 2
When a new file is created in the outputs "directory" in the same S3 bucket, it means the workload has finished processing, and all "data-processing"-tagged instances should now be identified and terminated.
Solution Using S3 Triggers and Lambda
As explained at Configuring Amazon S3 Consequence Notifications
, S3 can ship notifications upon:
- object creation
- object removal
- object restore
- replication events
- RRS failures
S3 can publish these events to 3 possible destinations:
- SNS
- SQS
- Lambda
Nosotros want S3 to button object creation notifications directly to a Lambda function, which will accept the necessary logic to process these events and decide further actions.
Hither's how to practise this using Python3 and boto3 in a unproblematic Lambda function.
AWS Console: Setup the S3 bucket
Get to the AWS S3 panel. Go to the bucket you want to utilise (or create a new one with default settings) for triggering your Lambda role.
Create three "folders" in this bucket ('folders/directories' in S3 are actually 'fundamental-prefixes' or paths) similar so:
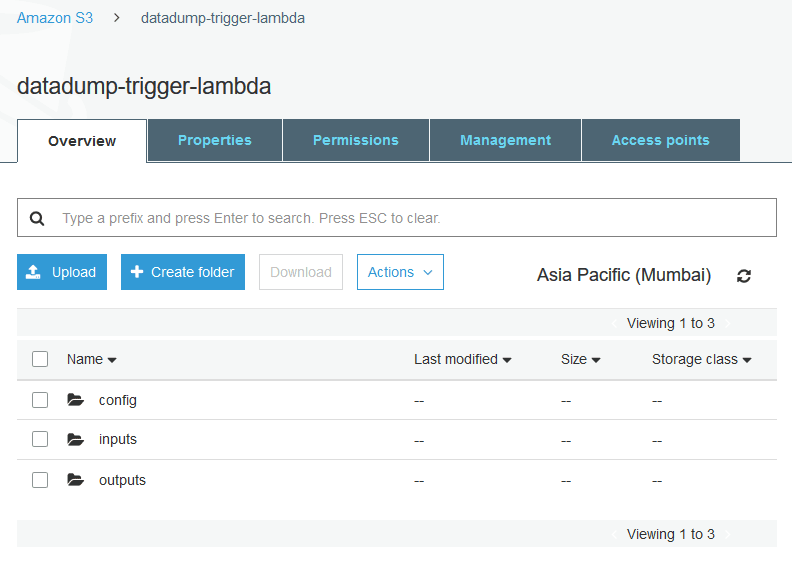
What are these dirs for?
-
config: to hold diverse settings for the Lambda function -
inputs: a CSV file uploaded hither will trigger the ML workload on an EC2 instance -
outputs: any file here indicates completion of the ML workload and should crusade any running information-processing (i.due east. especially-tagged) EC2 instances to terminate
The config folder
We need to supply the EC2 launch information to the Lambda function. By "launch information" nosotros mean, the instance-type, the AMI-Id, the security groups, tags, ssh keypair, user-information, etc.
One manner to practice this is to difficult-lawmaking all of this into the Lambda code itself, but this is never a good thought. It'due south ever better to externalize the config, and one style to exercise this past storing it in the S3 bucket itself like so:
Salve this every bit ec2-launch-config.json in the config folder:
{ "ami" : "ami-0123b531fc646552f" , "region" : "ap-s-1" , "instance_type" : "t2.nano" , "ssh_key_name" : "ssh-connect" , "security_group_ids" : [ "sg-08b6b31110601e924" ], "filter_tag_key" : "Purpose" , "filter_tag_value" : "information-processing" , "set_new_instance_tags" : [ { "Key" : "Purpose" , "Value" : "data-processing" }, { "Central" : "Name" , "Value" : "ML-runner" } ] }
The params are quite cocky-explanatory, and yous can tweak them equally you lot need to.
"filter_tag_key": "Purpose" : "filter_tag_value": "data-processing" --> this is the tag that volition be used to place (i.east. filter) already-running data-processing EC2 instances.
You lot'll notice that user-information isn't part of the above JSON config. It's read in from a separate file called user-data, simply so that it's easier to write and maintain:
#!/bin/bash apt-get update -y apt-go install -y apache2 systemctl start apache2 systemctl enable apache2.service echo "Congrats, your setup is a success!" > /var/www/html/index.html
The above user-information script will install the Apache2 webserver, and writes a congratulatory bulletin that volition be served on the instance's public IP address.
Lambda function logic
The Lambda function needs to:
- receive an incoming S3 object cosmos notification JSON object
- parse out the S3 bucket name and S3 object key name from the JSON
- pull in a JSON-based EC2 launch configuration previously stored in S3
- if the S3 object key (i.e. "directory") matches
^inputs/, cheque if we need to launch a new EC2 instance and if so, launch i - if the S3 object primal (i.east. "directory") matches
^outputs/, terminate any running tagged instances
AWS Console: New Lambda function setup
Get to the AWS Lambda console and click the Create office push button.
Select Author from scratch, enter a function name, and select Python 3.8 as the Runtime.
Select Create a new part with bones Lambda permissions in the Choose or create an execution function dropdown.
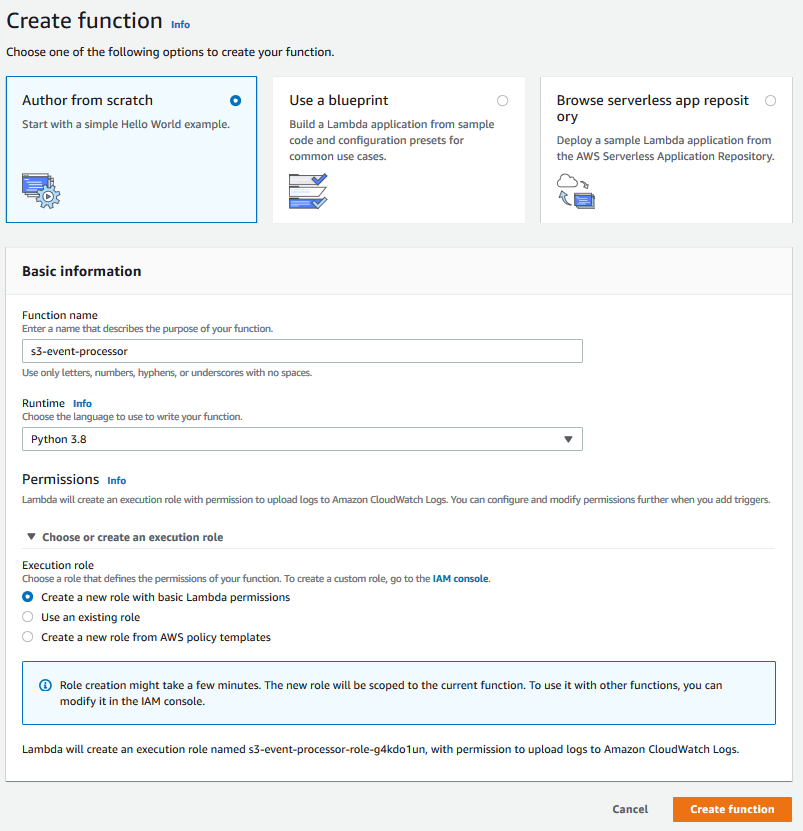
Click the Create part button.
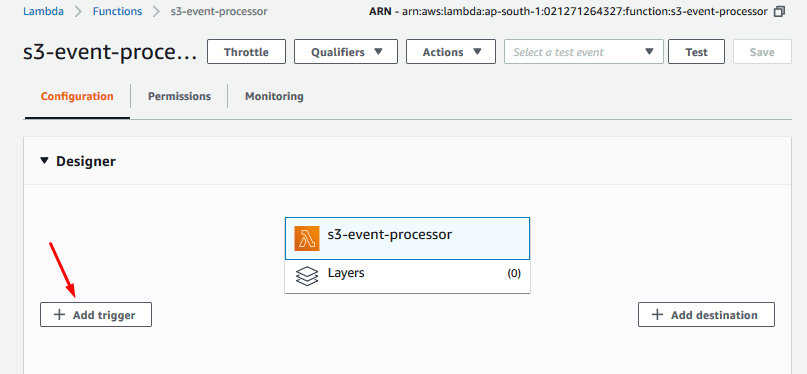
This will take y'all to the Configuration tab.
Click the Add Trigger button:
Setup an S3 trigger from the bucket in question, like so:
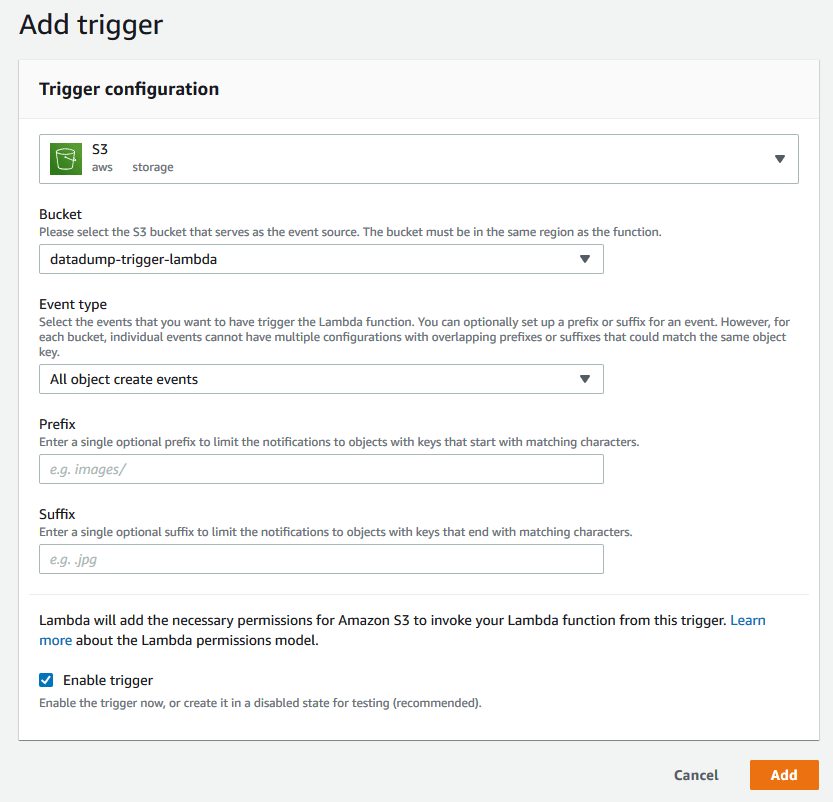
- Select your saucepan
- Select the events you lot're interested in (
All object create eventsin this example) - Leave
PrefixandSuffixempty, every bit we will have intendance of prefixes (inputsandoutputsbucket paths) in our role - Select
Enable trigger
As it says most the bottom of the screenshot:
Lambda volition add together the necessary permissions for Amazon S3 to invoke your Lambda function from this trigger.
And then we don't demand to become into S3 to configure notifications separately.
- Click the
Addbutton to save this trigger configuration.
Back on the main Lambda designer tab, you'll find that S3 is now linked upward to the our newly-created Lambda function:

Click the name of the Lambda function to open up the Function code editor underneath the Designer pane.
Lambda function code
Copy the following Lambda function lawmaking into the Function code editor, then click the Save button on the top-right.
import boto3 import json import base64 from urllib.parse import unquote_plus BUCKET_NAME = "YOUR_S3_BUCKET_NAME" CONFIG_FILE_KEY = "config/ec2-launch-config.json" USER_DATA_FILE_KEY = "config/user-data" BUCKET_INPUT_DIR = "inputs" BUCKET_OUTPUT_DIR = "outputs" def launch_instance ( EC2 , config , user_data ): tag_specs = [{}] tag_specs [ 0 ][ 'ResourceType' ] = 'instance' tag_specs [ 0 ][ 'Tags' ] = config [ 'set_new_instance_tags' ] ec2_response = EC2 . run_instances ( ImageId = config [ 'ami' ], # ami-0123b531fc646552f InstanceType = config [ 'instance_type' ], # t2.nano KeyName = config [ 'ssh_key_name' ], # ambar-default MinCount = ane , MaxCount = 1 , SecurityGroupIds = config [ 'security_group_ids' ], # sg-08b6b31110601e924 TagSpecifications = tag_specs , # UserData=base64.b64encode(user_data).decode("ascii") UserData = user_data ) new_instance_resp = ec2_response [ 'Instances' ][ 0 ] instance_id = new_instance_resp [ 'InstanceId' ] # print(f"[DEBUG] Full ec2 instance response data for '{instance_id}': {new_instance_resp}") return ( instance_id , new_instance_resp ) def lambda_handler ( raw_event , context ): impress ( f "Received raw event: { raw_event } " ) # event = raw_event['Records'] for record in raw_event [ 'Records' ]: bucket = record [ 's3' ][ 'bucket' ][ 'name' ] print ( f "Triggering S3 Bucket: { bucket } " ) key = unquote_plus ( record [ 's3' ][ 'object' ][ 'primal' ]) impress ( f "Triggering key in S3: { key } " ) # get config from config file stored in S3 S3 = boto3 . client ( 's3' ) effect = S3 . get_object ( Bucket = BUCKET_NAME , Key = CONFIG_FILE_KEY ) ec2_config = json . loads ( event [ "Torso" ]. read (). decode ()) print ( f "Config from S3: { ec2_config } " ) ec2_filters = [ { 'Proper name' : f "tag: { ec2_config [ 'filter_tag_key' ] } " , 'Values' :[ ec2_config [ 'filter_tag_value' ] ] } ] EC2 = boto3 . client ( 'ec2' , region_name = ec2_config [ 'region' ]) # launch new EC2 instance if necessary if bucket == BUCKET_NAME and fundamental . startswith ( f " { BUCKET_INPUT_DIR } /" ): print ( "[INFO] Describing EC2 instances with target tags..." ) resp = EC2 . describe_instances ( Filters = ec2_filters ) # print(f"[DEBUG] describe_instances response: {resp}") if resp [ "Reservations" ] is not []: # at to the lowest degree one instance with target tags was found for reservation in resp [ "Reservations" ] : for instance in reservation [ "Instances" ]: print ( f "[INFO] Establish ' { instance [ 'State' ][ 'Name' ] } ' case ' { example [ 'InstanceId' ] } '" f " having target tags: { instance [ 'Tags' ] } " ) if instance [ 'State' ][ 'Code' ] == sixteen : # instance has target tags AND also is in running state print ( f "[INFO] instance ' { instance [ 'InstanceId' ] } ' is already running: and then non launching any more instances" ) return { "newInstanceLaunched" : False , "old-instanceId" : instance [ 'InstanceId' ], "new-instanceId" : "" } print ( "[INFO] Could not find even a single running instance matching the desired tag, launching a new 1" ) # retrieve EC2 user-data for launch result = S3 . get_object ( Bucket = BUCKET_NAME , Key = USER_DATA_FILE_KEY ) user_data = result [ "Body" ]. read () print ( f "UserData from S3: { user_data } " ) upshot = launch_instance ( EC2 , ec2_config , user_data ) impress ( f "[INFO] LAUNCHED EC2 instance-id ' { result [ 0 ] } '" ) # impress(f"[DEBUG] EC2 launch_resp:\n {effect[1]}") render { "newInstanceLaunched" : Truthful , "old-instanceId" : "" , "new-instanceId" : outcome [ 0 ] } # terminate all tagged EC2 instances if bucket == BUCKET_NAME and key . startswith ( f " { BUCKET_OUTPUT_DIR } /" ): print ( "[INFO] Describing EC2 instances with target tags..." ) resp = EC2 . describe_instances ( Filters = ec2_filters ) # print(f"[DEBUG] describe_instances response: {resp}") terminated_instance_ids = [] if resp [ "Reservations" ] is non []: # at least one example with target tags was found for reservation in resp [ "Reservations" ] : for instance in reservation [ "Instances" ]: print ( f "[INFO] Constitute ' { instance [ 'State' ][ 'Name' ] } ' instance ' { instance [ 'InstanceId' ] } '" f " having target tags: { instance [ 'Tags' ] } " ) if instance [ 'State' ][ 'Code' ] == xvi : # case has target tags AND besides is in running land print ( f "[INFO] example ' { example [ 'InstanceId' ] } ' is running: terminating information technology" ) terminated_instance_ids . append ( instance [ 'InstanceId' ]) boto3 . resource ( 'ec2' ). Instance ( instance [ 'InstanceId' ]). stop () return { "terminated-instance-ids:" : terminated_instance_ids }
Lambda Execution IAM Role
Our lambda function won't work just yet. It needs S3 access to read in the config and information technology needs permissions to describe, launch, and terminate EC2 instances.
Scroll down on the Lambda configuration page to the Execution office and click the View role link:
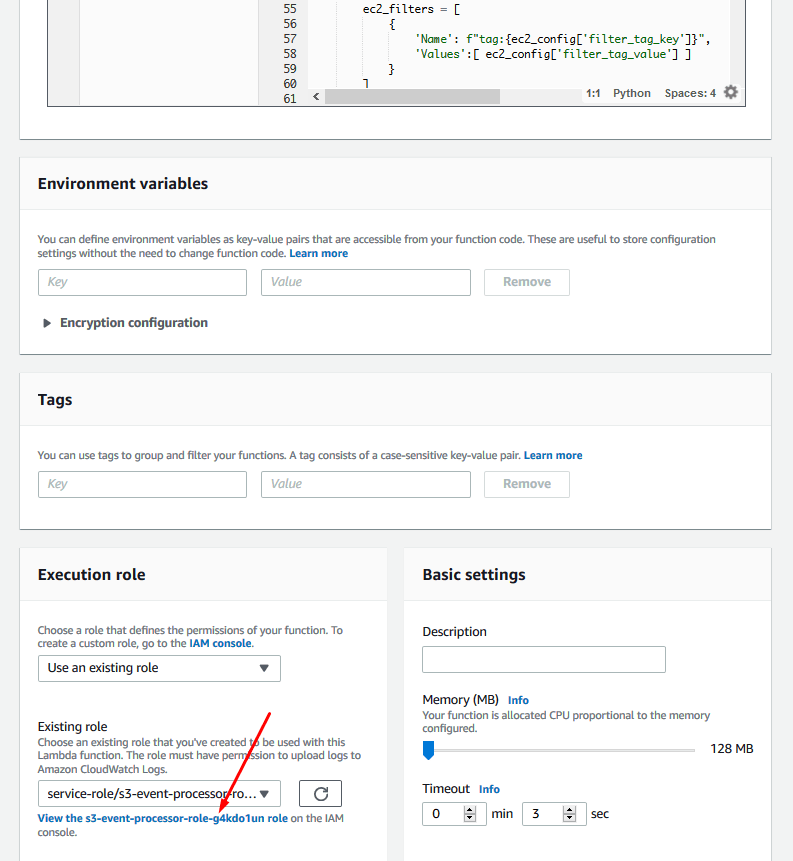
Click on the AWSLambdaBasic... link to edit the lambda function'south policy:
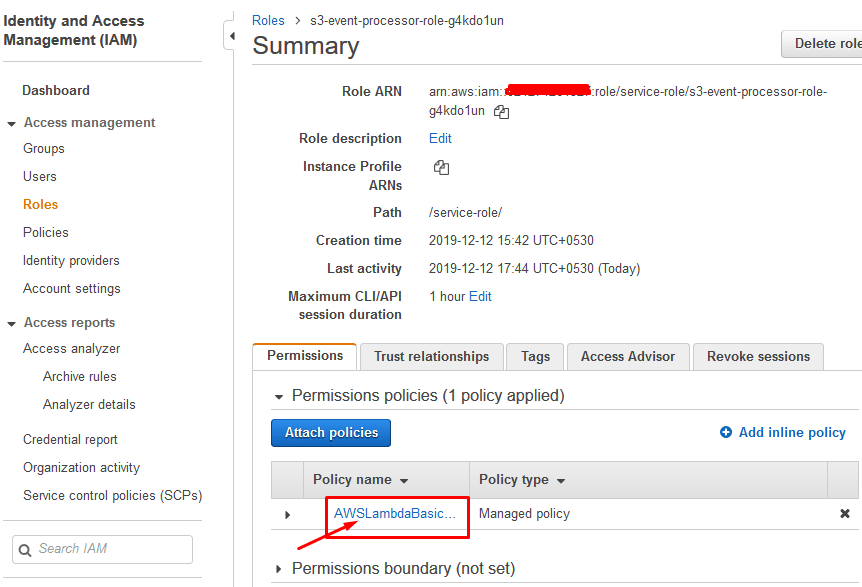
Click {} JSON, Edit Policy and and then JSON.
Now add the following JSON to the existing Statement Section
{ "Issue" : "Allow" , "Activeness" : [ "s3:*" ], "Resource" : "*" } , { "Action" : [ "ec2:RunInstances" , "ec2:CreateTags" , "ec2:ReportInstanceStatus" , "ec2:DescribeInstanceStatus" , "ec2:DescribeInstances" , "ec2:TerminateInstances" ], "Effect" : "Allow" , "Resource" : "*" }
Click Review Policy and Save changes.
Become!
Our setup'due south finally consummate. We're set up to test it out!
Test Case 1: new instance launch
Upload a file from the S3 console into the inputs folder. If you lot used the verbal aforementioned config as to a higher place, this would take triggered the Lambda function, which in turn would accept launched a new t2.nano instance with the Purpose: data-processing tag on it.
If you put the case's public IP accost into a browser (after giving information technology a minute or then to boot and warm up), yous should likewise see the test bulletin served to you lot: which indicates that the user-data did indeed execute successfully upon boot.

Test Case 2: another instance should not launch
As long as there is at least one Purpose: information-processing tagged instance running, another one should not spawn. Let'due south upload some other file to the inputs folder. And indeed the bodily behavior matches the expectation.
If we kill the already-running case, and then upload another file to the inputs folder, it volition launch a new example.
Test Example 3: case termination condition
Upload a file into the outputs folder. This volition trigger the Lambda function into terminating any already-running instances that are tagged with Purpose: data-processing.
Bonus: S3 event object to test your lambda function
S3-object-creation-notification (to examination Lambda role)
{ "Records" : [ { "eventVersion" : "two.1" , "eventSource" : "aws:s3" , "awsRegion" : "ap-south-1" , "eventTime" : "2019-09-03T19:37:27.192Z" , "eventName" : "ObjectCreated:Put" , "userIdentity" : { "principalId" : "AWS:AIDAINPONIXQXHT3IKHL2" }, "requestParameters" : { "sourceIPAddress" : "205.255.255.255" }, "responseElements" : { "x-amz-asking-id" : "D82B88E5F771F645" , "ten-amz-id-ii" : "vlR7PnpV2Ce81l0PRw6jlUpck7Jo5ZsQjryTjKlc5aLWGVHPZLj5NeC6qMa0emYBDXOo6QBU0Wo=" }, "s3" : { "s3SchemaVersion" : "1.0" , "configurationId" : "828aa6fc-f7b5-4305-8584-487c791949c1" , "bucket" : { "name" : "YOUR_S3_BUCKET_NAME" , "ownerIdentity" : { "principalId" : "A3I5XTEXAMAI3E" }, "arn" : "arn:aws:s3:::lambda-artifacts-deafc19498e3f2df" }, "object" : { "fundamental" : "b21b84d653bb07b05b1e6b33684dc11b" , "size" : 1305107 , "eTag" : "b21b84d653bb07b05b1e6b33684dc11b" , "sequencer" : "0C0F6F405D6ED209E1" } } } ] }
That's all, folks!
Source: https://dev.to/nonbeing/upload-file-to-s3-launch-ec2-instance-7m9
0 Response to "Upload File to Ec2 Instance Boto Python"
Post a Comment